
0.引入知识
一些量词如下:
| 名称 | 中文名 | 大小 |
|---|---|---|
| bit | 比特 | 1位(1b) |
| byte | 字节 | 8位(1B) |
| word | 字 | 16位 |
| dword | 双字 | 32位 |
| qword | 四字 | 64位 |
当前主流计算机的最小寻址单位是B(字节)而非b(比特)。
1.汇编语言的诞生
计算机并不能够直接执行高级语言,计算机真正能够执行的是机器码。但是一连串的机器码并不方便人阅读,因此最早将计算机数据以十六进制的格式书写。即便如此,十六进制字符的可读性依然很差。于是便诞生了汇编语言。
汇编语言就是把这些机器指令代码以一个助记符的形式翻译一下来方便人阅读。因此,汇编语言就是机器码的一个助记符。而高级语言是在这之后才诞生的。
2.寄存器
- 计算机的指令都是由CPU(中央处理单元)来执行。
- 在计算机系统结构中,CPU和内存是分开的。
- 寄存器存在于CPU中,是CPU的直接操作对象。
寄存器的种类如下图: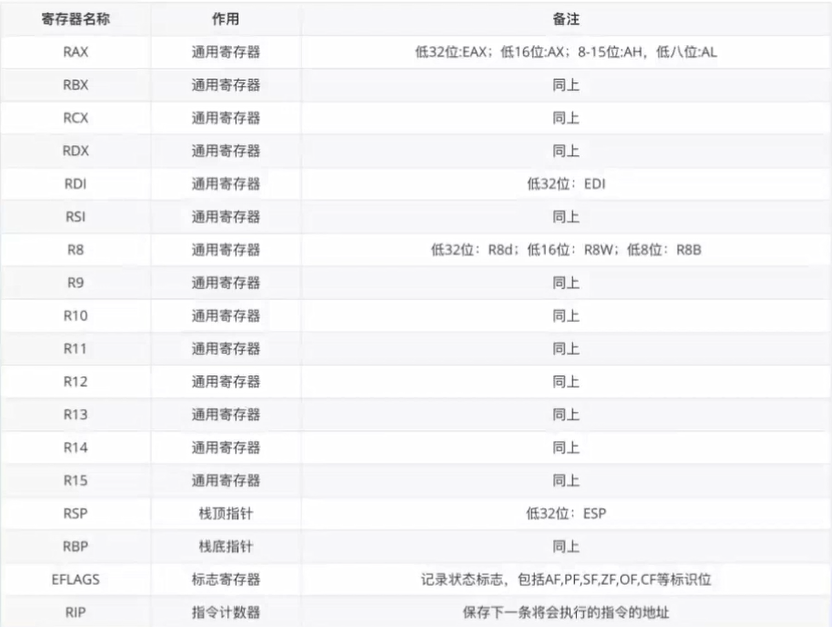
通用寄存器通常用于参数传递以及算数运算等通用场合。
RSP为栈顶指针,RBP为栈底指针,二者用于维护程序运行时的函数栈。(调用约定)
EFLAGS为标志位寄存器,用于存储CPU运行计算过程中的状态,如进位溢出等。
RIP指针用于存储CPU下一条将会执行的指针,无法直接修改。正常情况下会每一次运行一条指令自增一条指令的长度,当发生跳转时才会以其他形式改变其值。
寻址方式如下图: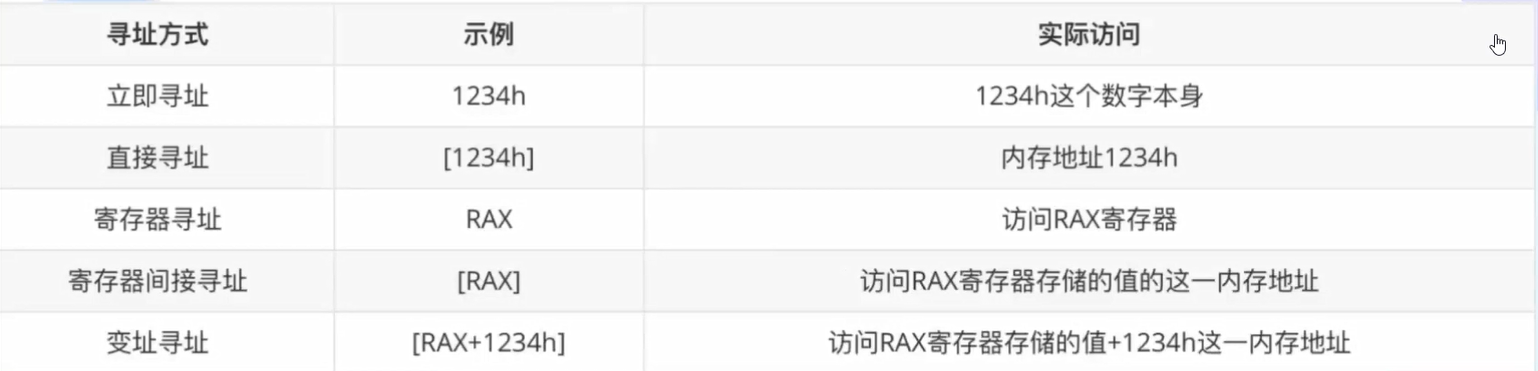
3.汇编指令
- 计算机只能完成很基本的操作,这些操作大多是对一些寄存器的值进行修改。
- 这些指令通过排列组合,完成复杂的功能。
- 两种格式:Intel、AT&T(区别在于源和目的操作数顺序上,可以通过立即数寻址来判断)
常见的汇编指令见下图: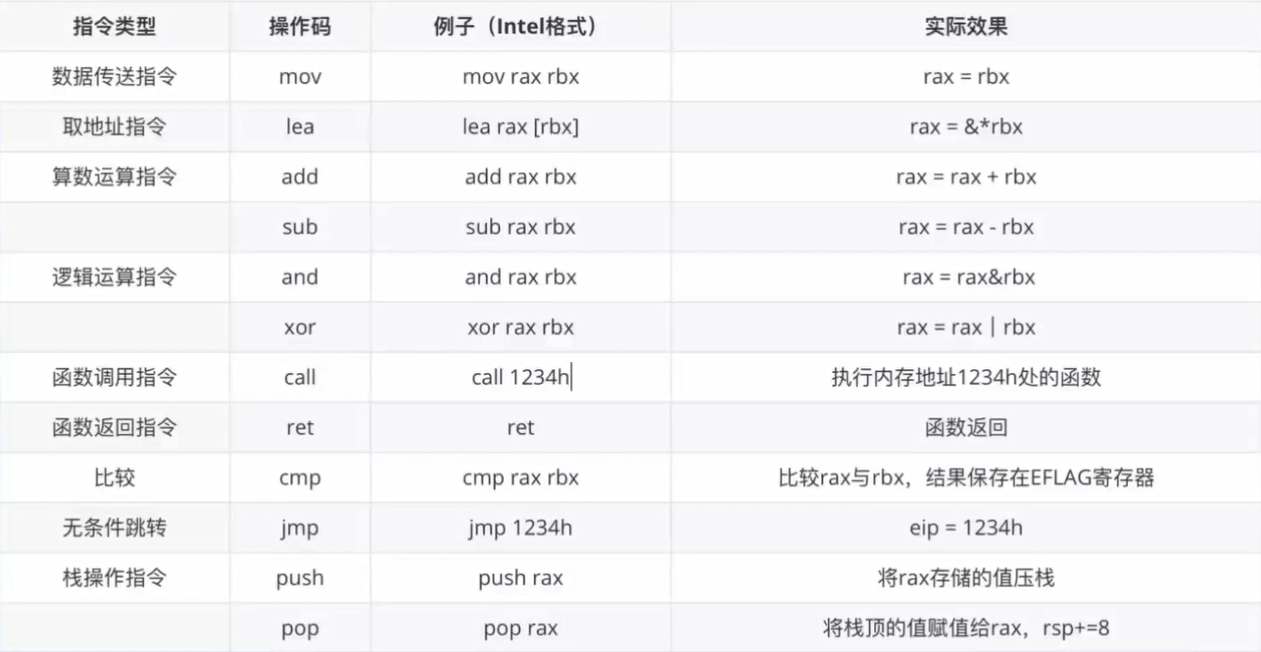
(我总感觉lea的那个实际效果是个非法语句?至少在C中是非法的……)
计算机在执行代码时只会顺序执行,并通过call、jmp、ret等这种指令来完成跳转。因此,汇编语言会经常因为跳转而导致可读性差一些。
来看一段C代码:
1 | int i=0; |
将其翻译为汇编后:
1 | mov rax,0 ;int i=0; |
这里的jge是通过eflag寄存器中的标志位来判断,而eflag标志位是通过之前的cmp来设置。
两种交换(swap)变量的方法:
1 | int a,b; //假设分别存放于rax和rbx中 |
转为汇编后,第一种相当于:
1 | mov rcx,rax ;int c=a; |
而第二种相当于:
1 | add rax,rbx ;a=a+b; |
个人理解是“b=a-b;”这步可以看成是“c=a;c=c-b;b=c;”这三步的缩写。这样比较好理解。
我做了一个表格,便于理解第二种方法寄存器中数值的变化(假设初始值分别为1和2),如下:
| rax | rbx | rcx | 执行指令 |
|---|---|---|---|
| 1 | 2 | 0 | |
| 3 | 2 | 0 | add rax,rbx |
| 3 | 2 | 3 | mov rcx,rax |
| 3 | 2 | 1 | sub rcx,rbx |
| 3 | 1 | 1 | mov rbx,rcx |
| 2 | 1 | 1 | sub rax,rbx |
可以看出,执行完操作后,RAX与RBX中的值进行了交换。
其实,从结果上看,可以直接用“xchg rax,rbx”来进行交换。
4.溢出
计算机不能存储无限大的数,每种类型数值都有上下限。如下图: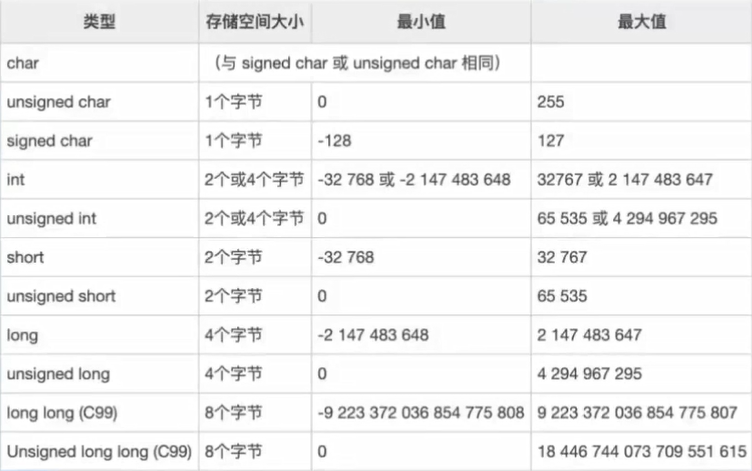
若是unsigned,数据的每一位都代表数据;若是signed,则数据的最高位会被当成符号处理,0代表正数,1代表负数。
既然数值有上下限范围,那么就不可避免会有溢出情况。
以32位int为例,有以下四种溢出:
- 无符号上溢:0xffffffff+1=0(按正常来说应该是0x100000000,但由于只有32位,因此最左边的1溢出)
- 无符号下溢:0-1=0xffffffff(道理同上)
- 有符号上溢:有符号正数0x7fffffff+1=负数0x80000000(进一到了符号位)
- 无符号下溢:有符号负数0x80000000-1=正数0x7fffffff(道理同上)
以上就是整数溢出。通常来说原因有两种:
1)存储数位不够。
2)溢出到符号位。
整数溢出一般配合别的漏洞来使用。
5.在PWN中的地位
汇编在CTF PWN中是必学的,但绝大部分情况下只要能看懂就行。(除了shellcode题)。通常是分析gadget。调试程序不需要分析每一条汇编指令,单步执行后查看寄存器状态即可。有时也可以IDA中F5查看伪C代码来规避。但很重要,必须学会!