
0.计算机内部的数据存储形式
计算机内部有两种数据存储形式:大端序、小端序。对于大端序而言,数据高位存储在计算机地址的低位,数据低位存储在地址的高位。而小端序正好相反,即数据高位存储在计算机地址的高位,数据低位存储在地址的低位。
可以简记成大端序高低低高,小端序高高低低。
以数据0x0123456789abcdef为例,0为低地址,7为高地址。
在大端序中,存储如下图:
将此数据以字符串输出,结果为:\x01\x23\x45\x67\x89\xab\xcd\xef
在小端序中,存储如下图:
将此数据以字符串输出,结果为:\xef\xcd\xab\x89\x67\x45\x23\x01


从输出的结果看,大端序符合人的阅读习惯;但从存储逻辑和数学运算规律看,小端序更正常。
因而Linux的数据存储格式为小端序。正因为Linux为小端序,因此在以字符串的形式输入一个数字时,要注意格式。(也有pwntools,p32可以完成自动转化)
1.栈(stack)
栈是一种LIFO(先进后出)的数据结构。栈的基本操作有两种:push(压栈)和pop(弹栈)。
由于函数的调用顺序也是LIFO,所以绝大多数系统都是通过栈这一数据结构来维护函数调用关系的。
为何函数调用顺序符合LIFO呢?
试想,我们在写C代码时,程序先从主函数main开始执行,而主函数中可能会调用其他函数,而这些函数中也有可能调用其他函数。只有在被调用的函数完成了之后,调用它的函数才会执行下一步操作,才有可能完成。因此主函数也是最后一个完成的。
可以很形象地类比为:我要煮饭(main)->我要先淘米(func_a)->我要先买米(func_b)->买完了米(func_b)->淘完了米(func_a)->煮完了饭(main)。
在Linux系统中,系统为每一个进程都安排了一个栈,进程中每一个调用的函数都有自己独立的栈帧。
栈是由高地址向低地址生长的。高地址为栈底,低地址为栈顶。
很多算法都是用栈实现的。以递归的形式实现一些算法在本质上来说也是利用栈结构。只不过没有在程序中另外申请一个栈,而是利用函数调用栈。
2.一些汇编指令的解释
- push:push指令的作用是压栈,将栈顶指针向上移动一个单位的距离,然后将一个寄存器的值放在栈顶。
(例如 push rax ,实际效果就是先 sub rsp,8 然后 mov [rsp],rax )
- pop:pop指令的作用是弹栈,将栈顶的数据弹出到寄存器,然后栈顶指针向下移动一个单位。
(例如 pop rax ,实际效果就是先 mov rax,[rsp] 然后 add rsp,8 )
- jmp:立即跳转,不涉及函数调用,用于循环、条件这种场合。
(例如 jmp 1234h ,效果就是 mov rip,1234h )
- call:函数调用,需要保存返回地址。
(例如 call 1234h ,效果为先 push rip 再 mov rip,1234h )
- ret:用于函数返回,相当于pop rip。
- leave:用于维护栈帧,通常出现在函数的结尾,与ret连用。其实际作用为先mov rsp,rbp再pop rbp。
3.函数调用流程
以下面代码为例:main调用func_b,func_b调用func_a。从主函数开始,以下逐步分析栈帧变化。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17void func_a()
{
//do sth.
return;
}
void func_b()
{
func_a();
int c=1;
return;
}
int main()
{
func_b();
int a=2;
return 0;
}
当运行到call func_b时主函数的栈帧如下图: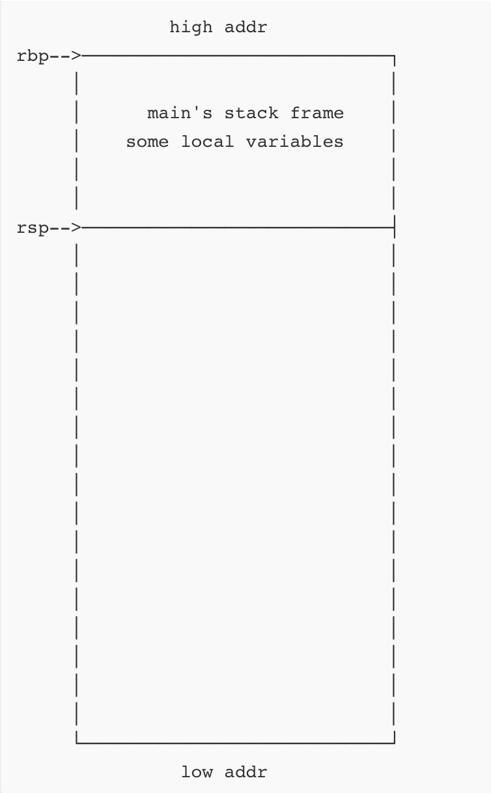
可以看出,此时rbp指向栈底,rsp指向栈顶。这段栈帧中存放了主函数的一些局部变量。当主函数要调用func_b时,只需要call func_b,即先push rip再mov rip,func_b。
此时跳转到func_b继续执行,但并非直接执行其主逻辑,被调用函数还要先维护栈帧。具体步骤如下: - push rbp ;将调用函数的栈底指针保存。
- mov rbp,rsp ;将栈底指针指向现在的栈顶。
- sub rsp,xxx ;开辟被调用函数的栈帧,此时上一步的rbp就指向栈帧的底。
func_b执行完维护栈帧操作后的栈布局如下图: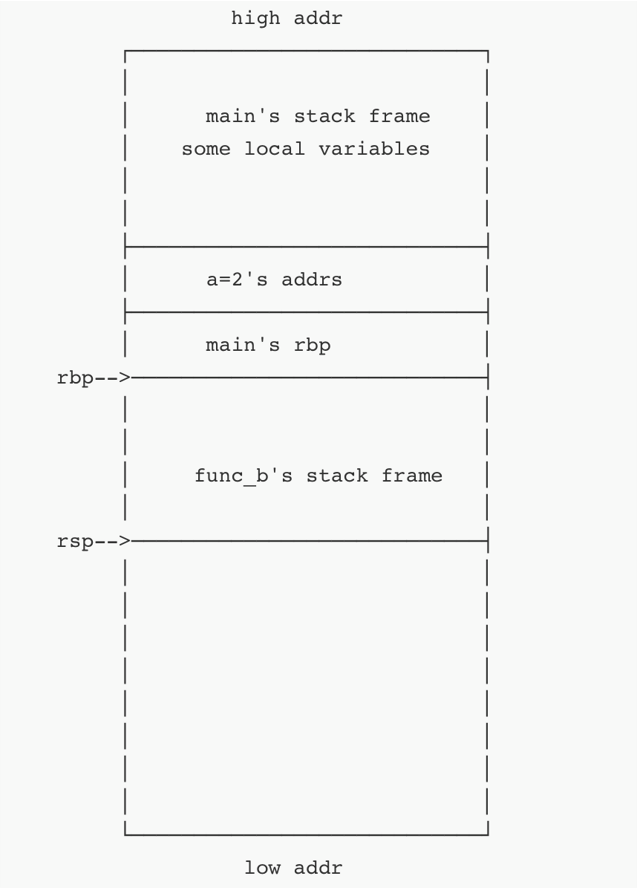
所谓栈帧的维护就是维护rbp和rsp两个指针。rsp永远指向栈顶。rbp用来定位局部变量。
之后,func_b调用func_a,其调用流程与主函数调用func_b基本一致。不同的是返回地址、rbp和rsp指向的地址,以及开辟的栈空间不同。
fanc_b调用完func_a后的栈布局如下图: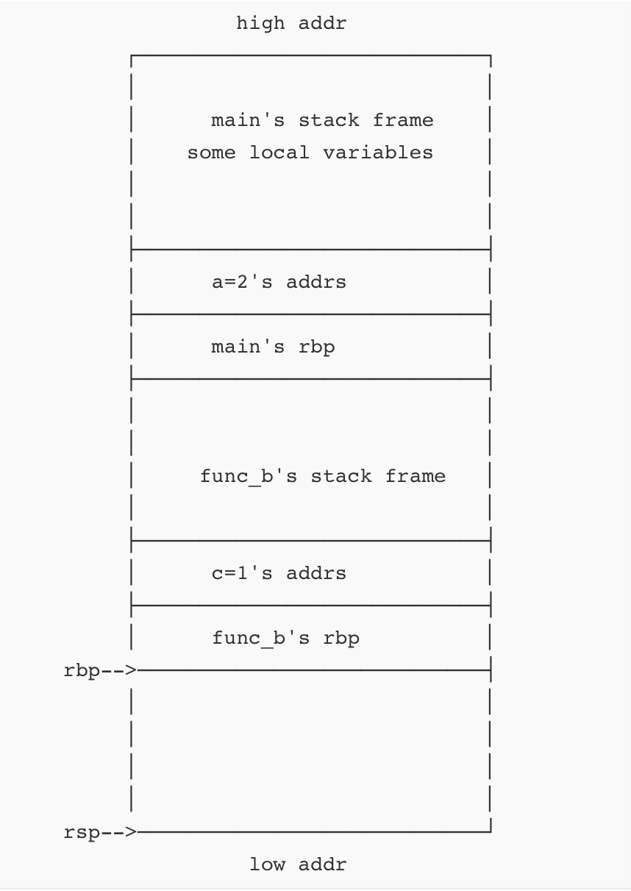
至此函数调用完毕。当func_a执行完毕后便要返回。当一个函数执行结束返回时,会执行leave和ret两个指令。这个过程的实际效果为先mov rsp,rbp再pop rbp最后再pop rip。
func_a执行完毕返回后的栈布局如下图:
可以看出,与之前func_b未调用func_a前的栈帧比完全一致,说明已经恢复了栈帧。但是唯一的不同之处是此时rip已经指向了c=1后面的一条指令,说明func_a已经执行完毕了。
同理,func_b执行完毕返回后的栈布局如下图:
之后主函数继续执行直到结束。
至此函数的调用返回执行流程结束。
总结如下:
- 调用函数:将rip压栈,然后将rip赋值为被调用函数的起始地址。这一操作被隐性地内置在call指令中。
- 被调用函数:先保存调用函数的rbp指针,将自己的rbp指针指向栈顶,然后开辟栈空间自用,此时rbp就成了被调用函数的栈底。
- 函数返回:恢复栈帧,返回调用函数的返回地址。
4.调用约定
一般来说,一个函数的返回值会存储到rax寄存器。
x86-64下函数的调用约定为: - 从左至右参数依次传递给rdi,rsi,rdx,rcx,r8,r9。
- 如果一个函数的参数大于六个,则从右至左压入栈中传递。(因为栈LIFO)
syscall指令用于调用系统函数,调用时需要指明系统调用号。系统调用号存在rax寄存器中。之后布置好参数,执行syscall即可。
系统调用的常用调用号码如下: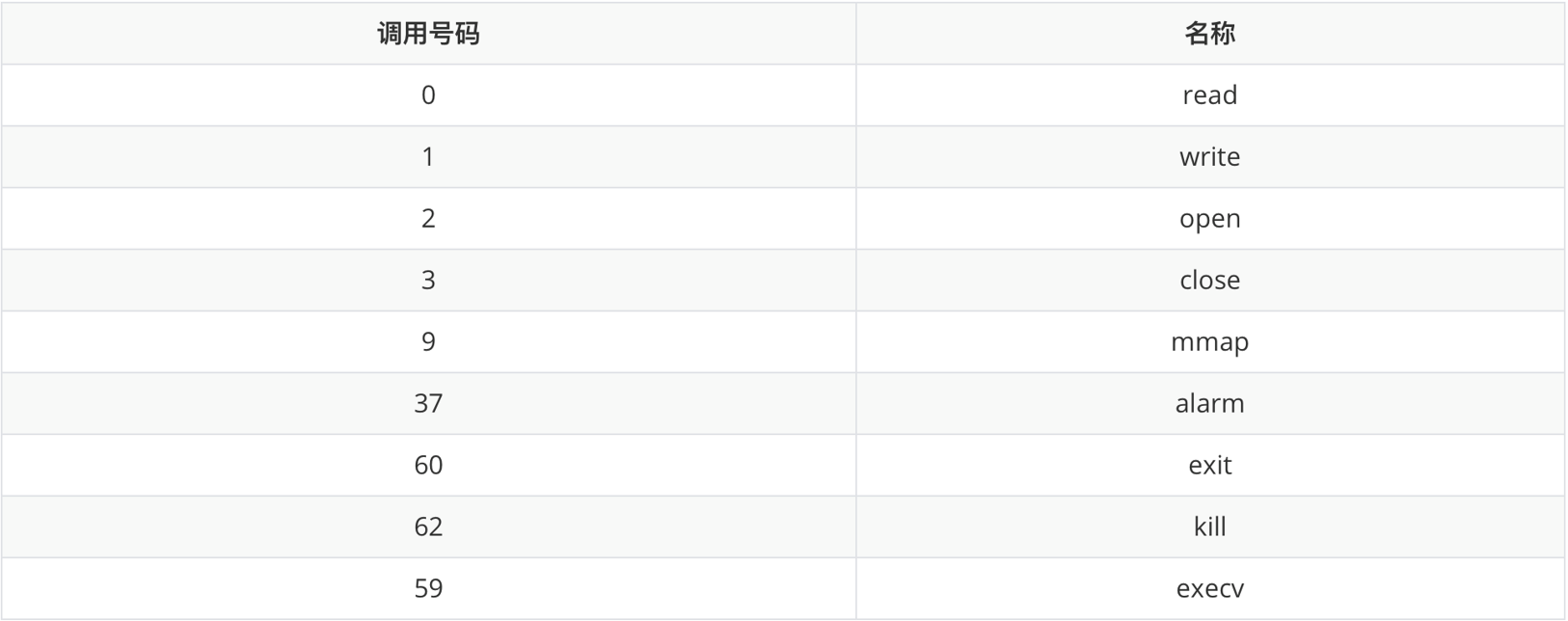
以调用read(0,buf,size)为例:
2
3
4
5
mov rdi,0 ;first arg.
mov rsi,buf ;second arg.
mov rdx,size ;third arg.
syscall ;excute read(0,buf,size);